



Озера даних та сховища даних – хмарні джерела для аналітики в режимі реального часу
 338
338Терміни «озеро даних» та «сховище даних» не перший рік на слуху і здаються чимось схожим. У цих типів репозиторіїв дійсне є багато схожого:
- акумуляція даних для потреб data science та аналітики;
- використання інформації для цілей бізнес аналізу та складання звітів;
- застосування хмарних технологій зберігання даних, що сприяють швидкому завантаженню та розповсюдженню.
Тому коли виникає необхідність вибирати між озерами та сховищами, у багатьох виникають складнощі. Давайте розберемося що це – Data Lake або озеро даних, позначимо ключові відмінності між різними типами репозиторіїв та визначимо, якому з них все-таки варто віддати перевагу, розглянувши важливі переваги та недоліки кожного з рішень. Також зі статті ви дізнаєтеся про ключові вендори та способи взаємодії з ними.
Що таке озеро даних?
Озеро даних – це велике сховище, здатне приймати будь-які обсяги даних у різних форматах. Сюди вони потрапляють у неструктурованому вигляді, не проходячи попередньої підготовки. Озеро даних не пред’являє до інформації, що завантажується, ніяких вимог і не має певної схеми її розміщення. Пошук у ньому здійснюється за допомогою тегів та унікальних ідентифікаторів. В результаті при створенні конкретного запиту система звертається тільки до релевантної частини інформації, що зберігається.
Спочатку метою створення озер даних була оптимізація традиційної технології зберігання. Data Lake дійсно позбавлена деяких її важливих недоліків – озера масштабуються, надають високу швидкість доступу до даних та є економічно ефективним рішенням. З їхньою допомогою можна працювати з аналітикою в режимі реального часу, взаємодіяти з Big Data, використовувати технології машинного навчання, будувати дашборди та створювати візуалізації. Такі сховища дозволяють запускати різні аналітичні процеси та надають доступ до максимального обсягу корисної інформації.
5 ключових переваг Data Lake
Інформація, що надходить до озера даних, не структурується. За рахунок такого підходу збільшується швидкість взаємодії з нею сторони інструментів self-service BI та аналітиків. Система не слідує за каталогом, збираючи по крихтах все необхідне, а отримує інформацію за потрібним запитом безпосередньо. Звідси випливають важливі переваги Data Lake:
- Простий доступ. При використанні озера даних немає потреби створювати складні запити та планувати моделі звернень до системи. Для ефективної взаємодії потрібно знати скільки даних, якого типу та з якого джерела потрібно «добути». Завдяки такій простоті, Data Lake може використовуватися користувачами безпосередньо за допомогою SQL-запитів, аналітичних програм, що використовують Big Data, а також є базою даних для машинного навчання.
- Оперативність. Оновлені дані завантажуються в озеро в режимі реального часу і можуть бути одразу імпортовані аналітичною системою. Завдяки цьому немає потреби впроваджувати складну схему взаємодії при розширенні потреб чи можливостей бізнесу. При цьому джерел, як і споживачів інформації, може бути декілька.
- Гнучкість аналітичних процедур. Зважаючи на відсутність будь-якої обробки вхідної інформації, ви можете впроваджувати нові методики аналізу або розширювати використання даних без внесення змін на рівні сховища.
- Масштабованість. Озера даних мають необмежений ресурс для зберігання інформації та можуть бути збільшені у розмірах без серйозних матеріальних інвестицій.
- Фінансовий зиск. Витрати на обслуговування Data Lake у порівнянні з іншими типами сховищ нижче, оскільки вони є простими в управлінні та не вимагають використання дорогого обладнання.
Саме відсутність структури та простота вихідних даних дозволяють комфортно взаємодіяти з Data Lake на рівні користувачів та різних аналітичних систем.
З чого складається озеро даних
Структуру Data Lake і процеси, що відбуваються всередині, простіше зрозуміти, поглянувши на схему:
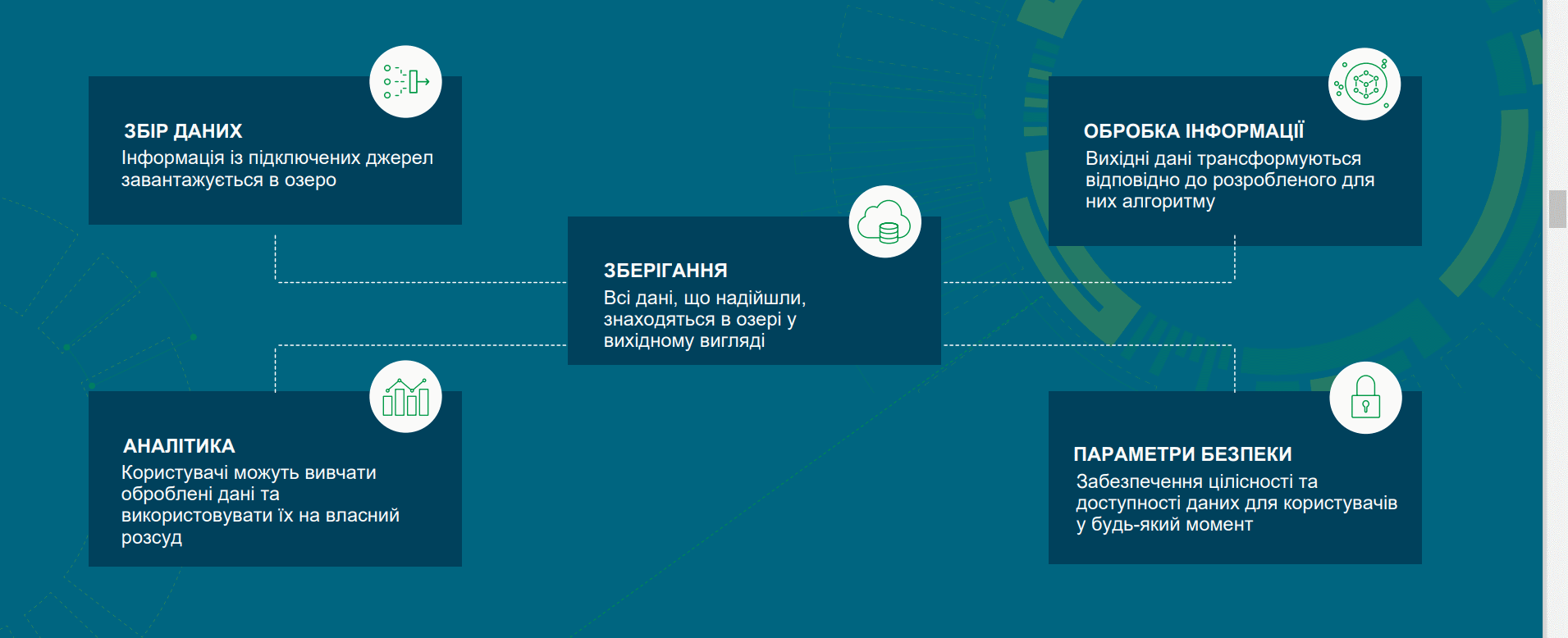
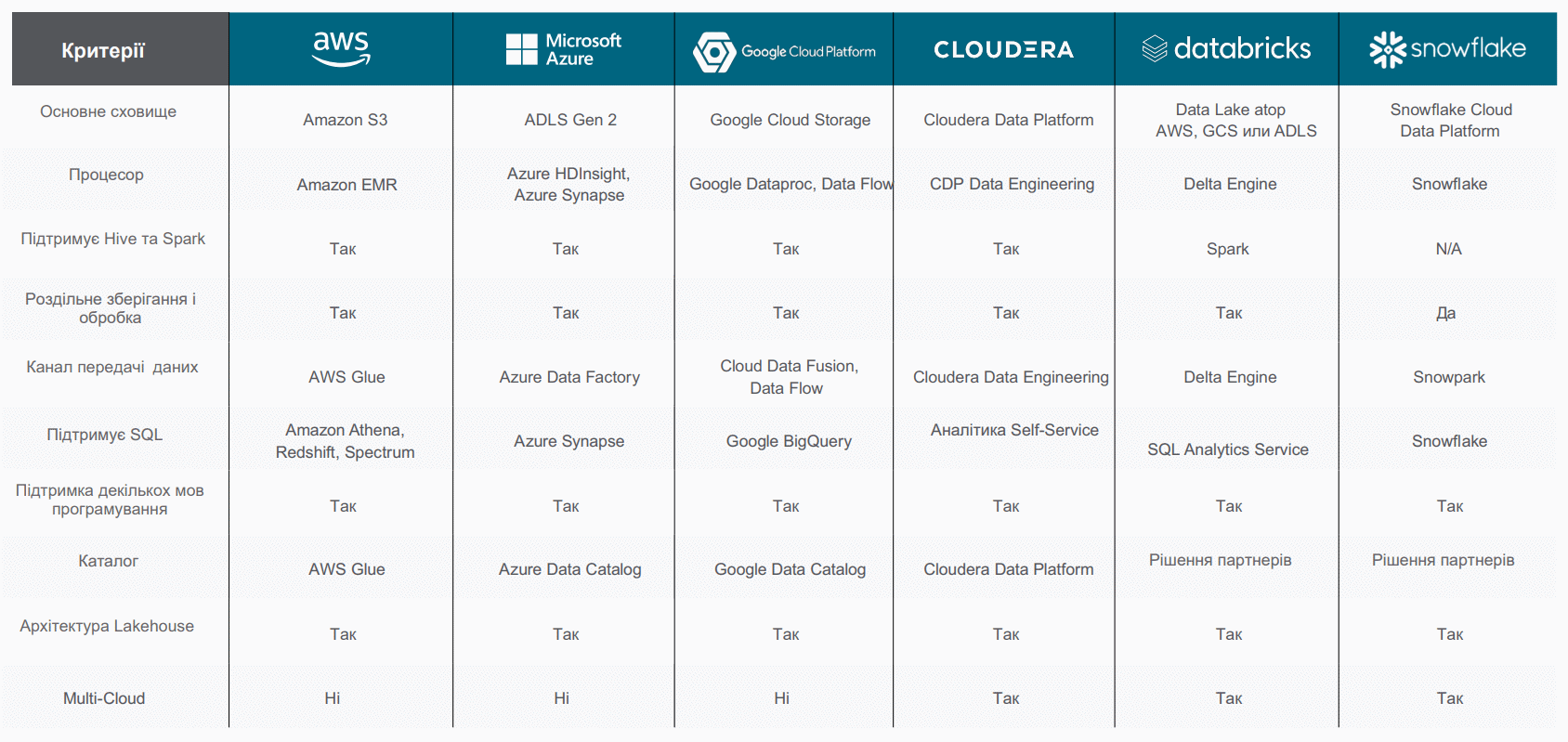
Функціонал Data Lake різних провайдерів може відрізнятися наявністю специфічних можливостей чи функцій. Порівняльний аналіз кількох найбільш популярних озер даних представлений у таблиці:
Що таке сховище даних?
Хмарне сховище – це централізоване місце зберігання структурованих даних, які повністю готові до використання в окремих аналітичних процесах. Інформація, що знаходиться, також може бути отримана з різних джерел. Відмінність із Data Lake полягає в тому, що вона приводиться в єдиний уніфікований формат.
На відміну від озера вміст сховища чітко структурований. Дані з нього можуть використовуватися у складанні звітів, ретроспективному аналізі, системах прийняття рішень, бути задіяними у технологіях машинного навчання. Завдяки хмарним сховищам з’явилася можливість масштабувати обсяги інформації, що накопичується, і оперативно отримувати доступ до потрібної інформації.
3 переваги використання хмарних сховищ
- У сховищі даних міститься вся інформація, необхідна бізнес аналітики. Його головними перевагами є:
- Висока якість інформації. Очищення та стандартизація даних дозволяє створювати єдине джерело правди для великої кількості користувачів та аналітичних процесів.
- Простий доступ до даних. Інформація чітко структурована і не потребує попередньої підготовки перед використанням.
Прискорена обробка даних. Завдяки уніфікації інформації аналітичні процедури виконуються набагато швидше. Ви зможете швидко вивчати інформацію та приймати ефективні управлінські рішення.
Усередині сховища не лише акумулюється, а й попередньо обробляється інформація. У результаті кінцевим споживачам немає необхідності додатково готувати дані до використання після вилучення.
Схематично архітектуру сховища можна зобразити так:
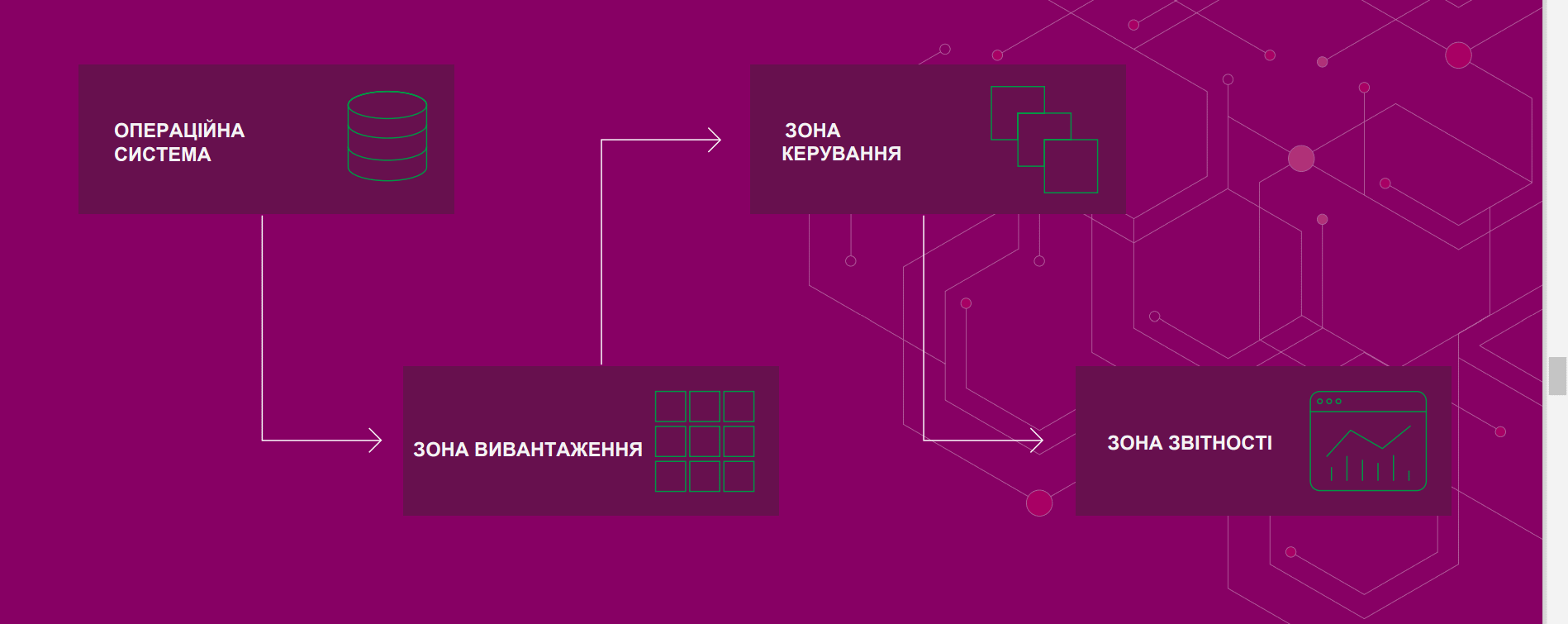
Нижче наведено порівняльну характеристику кращих хмарних сховищ

Яке рішення є оптимальним
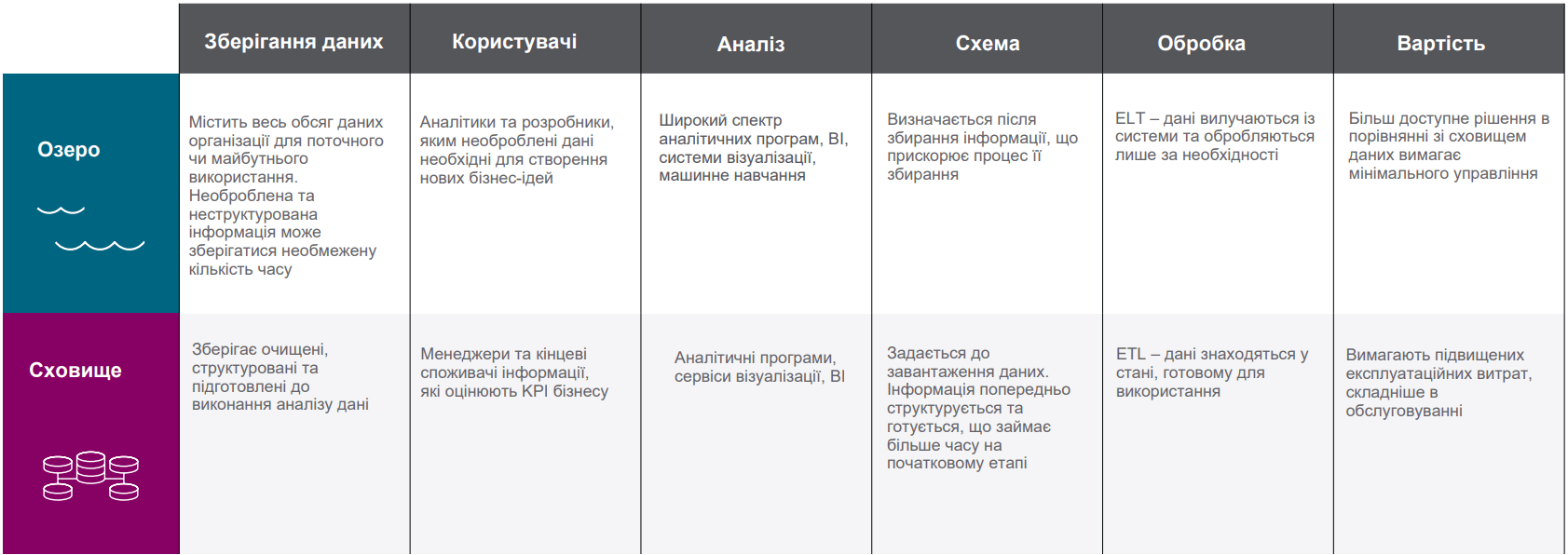
Data Lake та хмарні сховища даних можна використовувати як окремо, так і спільно. Нижче наведено порівняння цих рішень.
Інтеграція даних – ключ до успішної взаємодії з інформацією
Забезпечення безперервної передачі даних – важлива передумова ефективного використання різних систем зберігання. Реалізувати цю функцію необхідно як користувачам, які віддають перевагу хмарному сховищу даних, так і тим, кому підходить озеро.
За допомогою рішення Qlik Data Integration Platform ви зможете швидко акумулювати інформацію з різних джерел, керувати нею, уточнювати та обробляти. Платформа допомагає прискорити та оптимізувати процес передачі даних.
При використанні спільно з озерами Qlik автоматизує потоки даних із будь-яких джерел. На виході ви отримуєте інформацію готову для аналітики та не потребуєте додаткового програмування.
При спільному використанні хмарних сховищ та Qlik ви зможете автоматизувати його наповнення, що дозволить прискорити процеси підготовки даних. Фахівці з управління даними отримають можливість створення гнучкої внутрішньої структури та персональної моделі зберігання.
Qlik Data Integration – завжди свіжі дані
Актуальність інформації та можливість її швидкого поширення серед усіх учасників ухвалення рішень є ключовим фактором успіху. Використовуйте Qlik Data Integration – рішення, яке у мінімальні терміни виявляє нові дані та автоматизує процеси їх підготовки та передачі. З його допомогою інформація передається потоком як реального часу. Завдяки використанню Qlik Data Integration, ви зможете сформувати єдиний каталог даних самообслуговування для майбутньої аналітики. Рішення дозволяє не використовувати програмний код для таких завдань як створення, розгортання та проектування хмарних сховищ. З Qlik Data Integration ці операції можна виконувати вручну.
 23
23Аналітика більше не обмежується дашбордами. Розбираємо, як Agentic AI поєднує дані, контекст і дії, перетворюючи BI на систему, що допомагає приймати рішення в моменті.
 11
11Закупівлі можуть виглядати керованими — але саме тут часто непомітно втрачається маржа. У статті розбираємо, як аналітика допомагає побачити реальні причини витрат і почати ними управляти.


